Как скопировать текст
с картинки на компьютере:
12 эффективных инструментов
Статья рассказывает, как скопировать текст с картинки на компьютере и сохранить записи без искажений. В материале собраны способы, чтобы быстро извлечь отдельные фрагменты или все текстовое содержимое из картинок, скринов и PDF-документации.
Программы для копирования текста с картинки
Для решения задачи доступны десятки продуктов — от полноценных программ, которые устанавливаются на компьютер, до онлайн-сервисов, работающих прямо в браузере.
Принцип у них схожий: с помощью технологии OCR (оптического распознавания символов) они «читают» содержимое графических файлов и превращают его в редактируемый материал. Некоторые справляются с задачей в один клик, другие предлагают расширенные настройки — например, выбор языка или формат на выходе.
PDF Commander
Этот отечественный софт объединяет в себе сразу несколько функций, которые обычно распылены между разными утилитами. Пользователь может не только загрузить визуал или отсканировать бумаги, но и сразу вытащить текстовый блок с помощью встроенного распознающего модуля. Решение внесено в официальный Реестр российского ПО, а это уже сигнал о доверии на уровне министерств и госструктур.
Отличительная черта PDF Commander — продуманный сценарий работы с визуальными материалами. Скан, скриншот или обычное фото можно обрезать, повернуть, сохранить в любом варианте — от TXT до JPEG. Все это в одной среде, без необходимости открывать десяток вкладок или конвертировать данные вручную. Особенно ценят такой подход пользователи, которым потребовалось оцифровать бумажный архив или обработать поток входящей документации.
Как скопировать текст с фото на ПК через PDF Commander:
1. Запустите ПО и выберите «Создать PDF», далее «PDF из изображения».
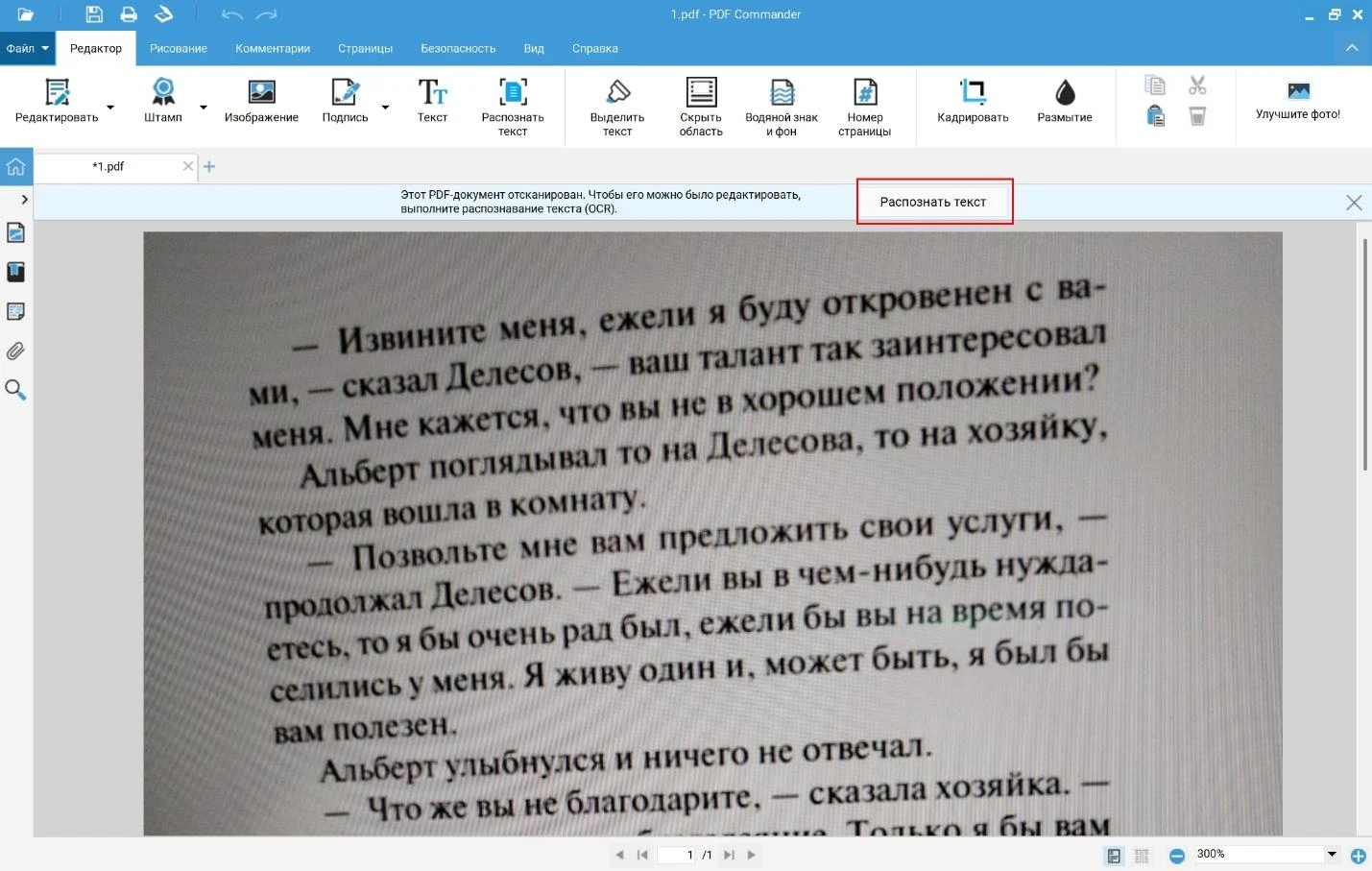
2. Добавьте нужный исходник с ПК. На странице автоматически появится предложение использовать OCR-опцию.
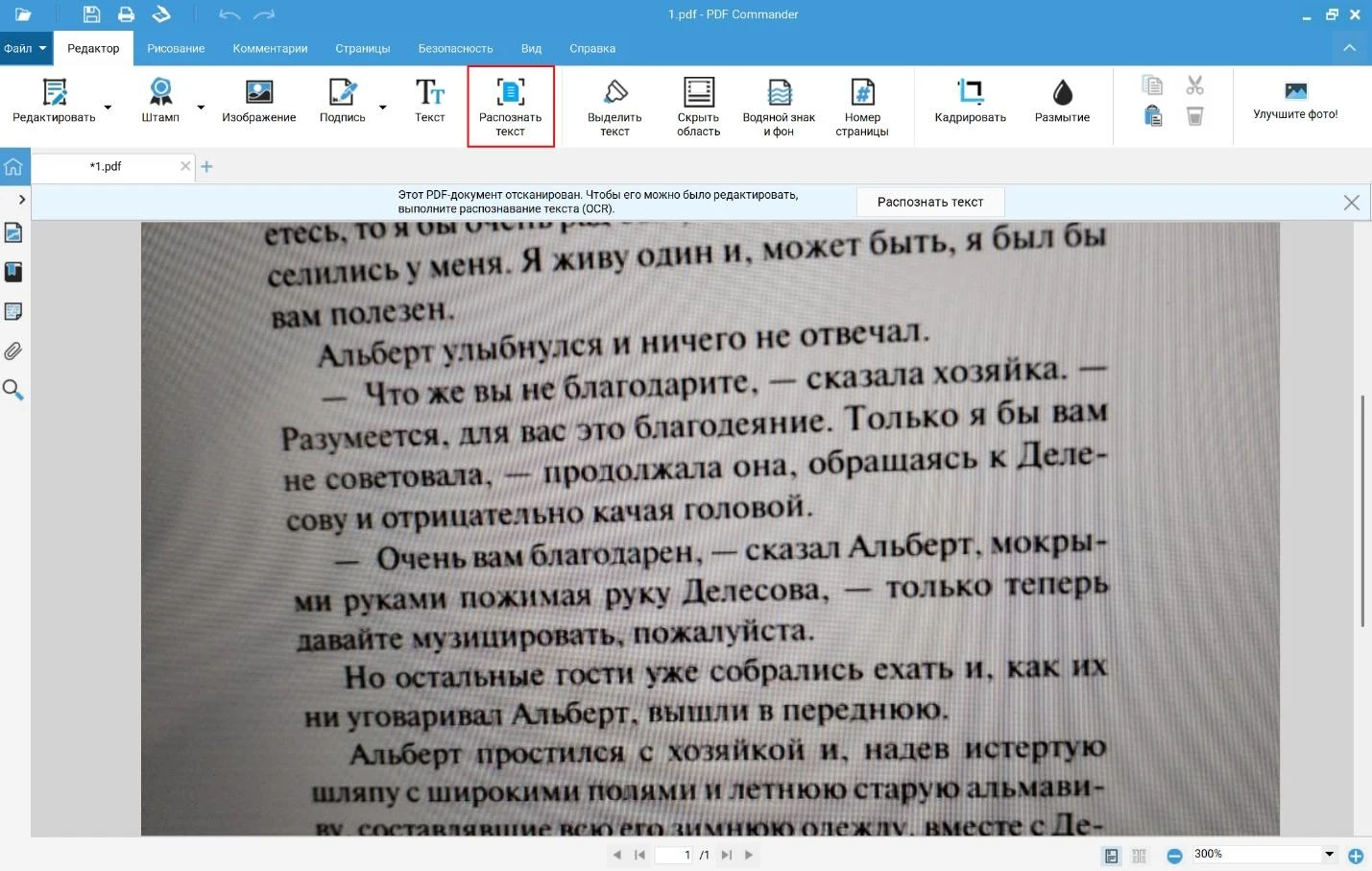
3. Также можно выбрать распознавание текстов в меню сверху.
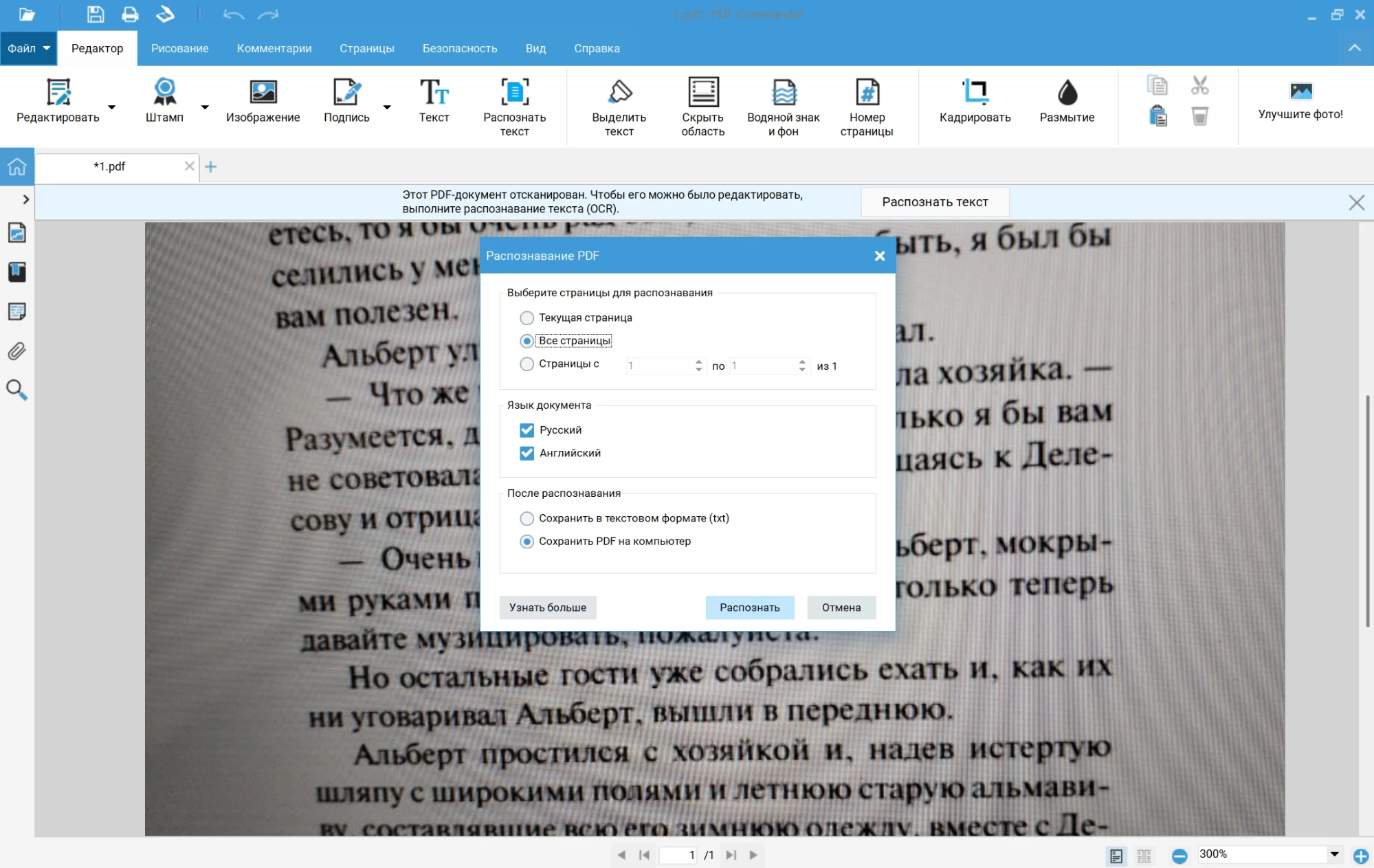
4. Укажите параметры работы: язык, формат сохранения, диапазон страниц с которыми нужно работать. Кликните на опцию запуска и дождитесь окончания обработки. ПО предложит выбрать папку для финальной загрузки.
Плюс:
- электронная подпись документов — можно заверить бумагу прямо в приложении;
- переформатирование в Excel, PNG, DOCX и другие — для быстрой адаптации;
- выделение областей для распознавания;
- программа понимает 100 языков;
- инструмент создания закладок и комментариев — полезен при изучении объемных PDF-документами.
Минусы:
- нет поддержки macOS — запустится только на Windows и Linux;
 Скачать бесплатно
Скачать бесплатно
 Поддержка систем: Windows 11, 10, 8, 7
Поддержка систем: Windows 11, 10, 8, 7
ABBYY FineReader PDF
Десктопное решение для распознавания из фото, ПДФ и отсканированных страниц. Поддерживает более 190 языков и умеет сохранять сложную внутреннюю структуру — таблицы, колонки, заголовки и списки. Включает инструменты редактирования, сравнения версий и сохранения в десятки форматов (DOCX, XLSX, HTML, RTF и др.). Может быть интегрировано с облачными хранилищами и используется в работе с юридическими, техническими и научными материалами. Устанавливается на Windows 10 и выше, требует около 1,6 ГБ пространства.
Как вытащить текст из картинки:
1. Запустите ПО, кликните «Открыть ПДФ/Изображение» на стартовом экране.
2. Отыщите элемент, после загрузки кликните «Распознавание».
3. Укажите язык и выберите вариант сохранения (например, Word).
4. После завершения нажмите «Сохранить как…».
Плюс:
- встроенный пользовательский словарь, который можно пополнять;
- сохранение таблиц, шрифтов и макета страницы без искажений;
- сравнение двух версий с отличиями.
Минусы:
- не получится оплатить из РФ;
- занимает много места и может тормозить на старых ПК и ноутбуках;
- необходима регистрация аккаунта.
CuneiForm
Приложение с открытым кодом, ориентированное на работу с кириллицей — особенно эффективно при взаимодействии со старыми печатными материалами, отсканированными книгами и учебниками. Поддерживает только русский, английский, украинский, но при этом обеспечивает стабильную работу даже на слабых ПК. Установка занимает менее 100 МБ, дизайн минималистичный: только нужные функции без лишней графики. Полученное можно сразу перегнать в Word или сохранить как .txt.
Как скопировать текст с фото на компьютере:
1. Откройте CuneiForm, кликните «Файл» → «Открыть изображение».
2. Выберите в меню «Язык» → «Русский» (или другой).
3. Нажмите «Распознать» на верхней панели инструментов.
4. После завершения кликните «Файл» → «Сохранить текст» или используйте кнопку Word на панели для экспорта.
Плюс:
- работает на Windows XP, 7, 10 и даже на Linux через эмулятор;
- поддерживает установку плагинов для расширения списка языков;
- экспорт в цифровой формат LaTeX.
Минусы:
- не поддерживает прямую работу с PDF-материалами — потребуется предварительно конвертировать в фото;
- нет пакетной обработки — по одному объекту за раз;
- дизайн может показаться устаревшим.
Readiris PDF
Коммерческая программа с OCR-модулем, предназначенная для офисной работы: умеет считывать текст, озвучивать его и сразу отправлять по почте. Особенность — функция преобразования в MP3 и ePub, благодаря чему документы можно слушать или читать на мобильных устройствах. Совместим с JPEG, PNG, TIFF, а также с данными, полученными со сканера. Поддерживает до 138 языков, доступен пакетный режим.
Как скопировать текст с фото на компьютере:
1. Откройте CuneiForm, кликните «Файл» → «Открыть изображение».
2. Выберите элемент, кликните «OCR» на панели сверху.
3. В появившемся меню задайте расширение (например, DOC)
4. Кликните «Convert» и затем сохраните через «File» → «Save As».
Плюс:
- русскоязычный интерфейс;
- есть извлечение текстовых фрагментов из выбранной области;
- пакетная обработка до 50 объектов за раз.
Минусы:
- бесплатная версия позволяет обрабатывать только 5 страниц;
- продукт частично переведен, часть модулей — на английском;
- не поддерживает редактирование без профессиональной подписки.
PDF Studio PRO
Бесплатное приложение, которое запускается офлайн и подходит для быстрого распознавания текста из фото и PDF-файлов. Использует собственный движок OCR.space, поддерживает кириллицу и не требует высокой мощности от компьютера. Берет содержимое с четких фото и сканированных страниц, сохраняет в TXT или PDF-формат, не загружая данные в облако.
Как выделить текст с фото и скопировать его:
1. Запустите ПО, нажмите кнопку «Open Image».
2. Загрузите элемент и выберите вариант из выпадающего списка.
3. Нажмите «OCR» — через несколько секунд появится результат.
4. Скопируйте его вручную или через «Export to TXT».
Плюс:
- многофункциональный редактор ПДФ;
- поддержка более 20 вариантов работы, включая русский, английский, немецкий;
- минимальная нагрузка — запускается даже на старых ноутбуках с 2 ГБ ОЗУ.
Минусы:
- не сохраняет структуру документа — колонки и таблицы теряются;
- нет перевода на русский;
- нет пакетной обработки — читает только по одному исходнику за раз.
Capture2Text
Минималистичное приложение, которое не требует установки и открывается прямо из системного трея. Оно позволяет обвести произвольную область экрана или весь материал и сразу скопировать его в буфер обмена. Это особенно удобно для OCR-извлечения из видео, презентаций или ПО без возможности копирования. Capture2Text не поддерживает загрузку файлов — только скриншоты в реальном времени.
Как извлечь текст:
1. Запустите .exe-файл, иконка появится рядом с часами.
2. Наведите мышь на интересующую часть экрана, зажмите комбинацию «Win + Q».
3. Обведите область, подождите — символы скопируются автоматически.
4. Вставьте их в нужное приложение (комбинацией «Ctrl + V»).
Плюс:
- работает «на лету»;
- поддержка горячих клавиш;
- совместим с Windows XP и выше, не требует прав администратора.
Минусы:
- только один язык за раз;
- новичкам продукт покажется сложным;
- отсутствует редактор.
Boxoft Free OCR
Бесплатная OCR-программа с классическим дизайном и возможностью считывания содержимого с картинок в JPEG, TIFF, BMP, PNG. Приложение не требует интернета и сохраняет содержимое с черно-белых и цветных сканов. Простой процесс извлечения, поддержка русского и возможность сразу экспортировать результат в текстовый редактор. ПО легкое (около 30 МБ), запускается на большинстве офисных ПК, разработано только под Windows.
Как скопировать текст с фотографии на компьютере:
1. Откройте софт, далее «Open» для загрузки фотоснимков.
2. Выберите объект и кликните «OCR» в верхнем меню.
3. Результат отобразится в правом окне — нажмите «Copy Text» или «Save As».
Плюс:
- автоматическая коррекция наклона сканов;
- совместим с многостраничными TIFF;
- простой экспорт в Word через кнопку «Export to Word».
Минусы:
- не видит PDF-материалы — требуется конвертация снимков заранее;
- максимум — один язык в настройках на весь сеанс распознавания;
- нет функции предварительного редактирования перед сохранением.
Сервисы для копирования информации с изображения
NewOCR
NewOCR — простой англоязычный сервис, позволяющий извлекать контент из фотографий и ПДФ прямо в браузере. Понимает кириллицу, не требует регистрации и отлично работает даже с отсканированными документами среднего качества. Можно загружать фото до 15 мегабайт и выделять содержимое. Итог можно сразу скопировать, отредактировать и скачать в .doc, .txt, .pdf.
Как извлечь текст:
1. Перейдите на сайт newocr.com.
2. Кликните «Choose File» и загрузите исходник.
3. Отметьте «Preview», затем выберите нужное в поле «Language».
4. Кликните «OCR» — результат появится в текстовом окне ниже.
5. Скопируйте необходимое или нажмите «Download» для экспорта.
Плюс:
- работает с PDF-файлами без ограничений;
- ручной выбор области для анализа;
- поддерживает даже арабскую письменность и японские иероглифы.
Минусы:
- все на английском;
- нет массовой обработки;
- не сохраняет форматирование оригинала.
OCRconvert.com
Универсальный веб-инструмент, который выделяет текстовые блоки из PDF и предлагает скачать результат в одном из популярных форматов — Word, Excel. Совместим с более чем 30 языками, включая русский, английский, немецкий и французский. Интерфейс минималистичный, без регистрации и рекламы. Есть автоматическое удаление всего загруженного спустя 24 часа.
Как извлечь текст:
1. Зайдите на сайт ocrconvert.com.
2. Кликните «Choose File», найдите снимок на компьютере.
3. Укажите требуемое в поле «Language», например Russian.
4. Кликните «Convert».
5. Нажмите «Download».
Плюс:
- поддержка экспорта в Excel, помимо стандартного TXT;
- можно использовать с телефона — адаптивный интерфейс;
- есть функция считывания по ссылке, можно не грузить документы вовсе.
Минусы:
- ограничение загрузки - 5 МБ;
- нет ручной настройки области анализа;
- не поддерживает многостраничные ПДФ.
i2OCR
Онлайн-сервис, понимающий более 100 шрифтов, включая кириллицу. Позволяет загружать изображения с компьютера или по URL, быстро понимает даже отсканированные исходники низкого качества. Возможен экспорт в TXT, DOC, при этом сохраняет пробелы, абзацы и часть форматирования. Интерфейс интуитивно понятный, не потребует учетной записи и работает в любых браузерах. Ограничение по размеру файла — до 10 МБ.
Как извлечь текст из картинки на компьютере:
1. Откройте сайт i2ocr.com.
2. Найдите необходимое в списке «Select OCR Language».
3. Кликните «Select Image» и загрузите исходное с компьютера.
4. Нажмите «Extract Text» — результат появится ниже.
5. Копируйте блок или нажмите «Download Output» для сохранения.
Плюс:
- можно распознавать по ссылке;
- сохраняет отступы и абзацы;
- позволяет выбрать перевод до начала загрузки — экономит время.
Минусы:
- нет пакетной загрузки — по одному за раз;
- PDF-файлы не поддерживаются напрямую;
- отсутствует выбор области на картинке.
Convertio OCR
Convertio — онлайн-сервис, узнает более 60 языков и дает выбор расширение загрузки: TXT, DOC или RTF. Уникальная особенность — можно загружать исходники не только с устройства, но и из облаков: Google Drive и Dropbox. Интерфейс переведен на русский, все действия выполняются пошагово через понятный мастер.
Как извлечь текст:
1. Зайдите на convertio.co/ocr.
2. Нажмите «Выбрать файлы» или загрузите необходимое из облачного хранилища.
3. Кликните «Распознать», дождитесь обработки.
4. Скачайте результат.
Плюс:
- интеграция с Google Drive и Dropbox;
- объем до 100 МБ (в платной версии);
- распознавание многостраничных ПДФ.
Минусы:
- в триал-версии ограничение — 10 МБ и 10 минут ожидания;
- без подписки нельзя обрабатывать более 2 элементов за раз;
- удаление загруженных на сайт документов делается только вручную.
OCR.Space Desktop
OCR.Space Desktop — легкое онлайн-приложение, которое позволяет быстро извлекать текст из изображений и PDF-документов без подключения к интернету. Программа поддерживает кириллицу и несколько десятков языков, а управление сведено к минималистичному набору действий: открыть файл, выбрать язык и запустить распознавание. Сохранять результат можно в текстовом или PDF-формате без потери качества исходника. Все это без долгой настройки.
Как извлечь текст:
1. Откройте OCR.Space Desktop на своем компьютере.
2. Кликните «Open Image» и выберите файл для обработки.
3. Выберите нужный язык распознавания.
4. Нажмите «Start OCR» и дождитесь окончания процесса.
5. Сохраните результат через «Export to TXT» или скопируйте вручную.
Плюс:
- нет необходимости в постоянном подключении к сети;
- поддержка форматов TIFF и BMP для продвинутой работы со сканами;
- сохранение данных только на локальном устройстве — максимум конфиденциальности.
Минусы:
- базовый экспорт без сохранения структуры таблиц и колонок;
- отсутствие редактирования текста;
- нет пакетной загрузки файлов.
Сравнительная таблица программ
Чтобы облегчить вам выбор, мы сравнили ПО в таблице. Разобрали ключевые факторы для каждого варианта.

PDF Commander

ABBYY FineReader PDF

CuneiForm

Readiris PDF

PDF Studio PRO
Capture2Text
Boxoft Free OCR
NewOCR
OCRconvert.com
i2OCR
Convertio OCR
OCR.Space Desktop


Заключение
Онлайн-сервисы вроде i2OCR или Convertio подойдут, если необходимо быстро вытащить нужное с одного-двух изображений без установки, а такие программы как ABBYY FineReader пригодятся в работе с отчетами и юридическими бумагами.
Но если говорить о повседневной практике — особенно когда дело касается сканов, картинок или фото — удобнее и выгоднее использовать PDF Commander. Он не только находит текстовые абзацы, но и позволяет сразу редактировать, кадрировать, добавлять комментарии, штампы и экспортировать в любой формат — все это в одном окне и без лишних действий.



Нужен многофункциональный редактор и конвертер для PDF?
Скачайте 100% рабочую версию!
Скачать бесплатно
Поддержка систем: Windows 11, 10, 8 и 7
Оставьте ваш комментарий
Cохраните себе статью, чтобы не потерять: